Tickets, please
Change is part of life whether we like it or not. Everybody reacts to it differently. There are some who resist it and some who embrace it.
It’s the same in the world of development. Some want everything in its right place before work begins. Others accept flexibility.
For most machine learning projects, change comes with the territory. Often, what may appear to be a straightforward piece of work actually turns out to be quite tricky and goal posts subtly shift during development.
The reason for this is often the data. Few people know it intimately before work begins, at least as far as the new requirements are concerned. And ask any data scientist what s/he thinks of the quality of their data (seriously, try it!). They’ll generally tell you it sucks.
As a result, there will be a back-and-forth with the business over what is to be done, what assumptions are acceptable and what consequences there may or may not be for the final product.
Developers are no strangers to this process but they’ve solved the problem. Software engineering uses ticketing systems to manage complexity (you’d be hard pressed to find a successful open source project that doesn’t). In a ticketing system, all the requirements can be documented and made available to any team member with a web browser. That means the business as well as the techies have a forum in which to horse-trade.
Common to all good ticketing systems are:
-
Audit logs. You need to know who said what and when, especially six months after the product goes live and you wonder why certain decisions were made.
-
Ticket numbers. Think of this as the primary key for the work, a lingua franca that makes communicating which work we’re talking about unambiguous. Disappointingly, not all ticketing systems provide these. The popular Asana does not have this functionality at the time of writing.
If your ticket system has these two properties then you can get:
Automatic documentation!
There’s a nice little trick you can do to link the code to the requirements. If the data scientists have a standard naming convention for the branches on which they work, their code can automagically be linked to the requirements. Free. No extra documentation needed.
Let’s take an example. Here is some code that was written years ago. Note that every line of code is associated with a ticket number via source control (Git, in our case). Your favourite development environment will generally show this as we can see below. Here we’re using the data scientist’s favourite: PyCharm:
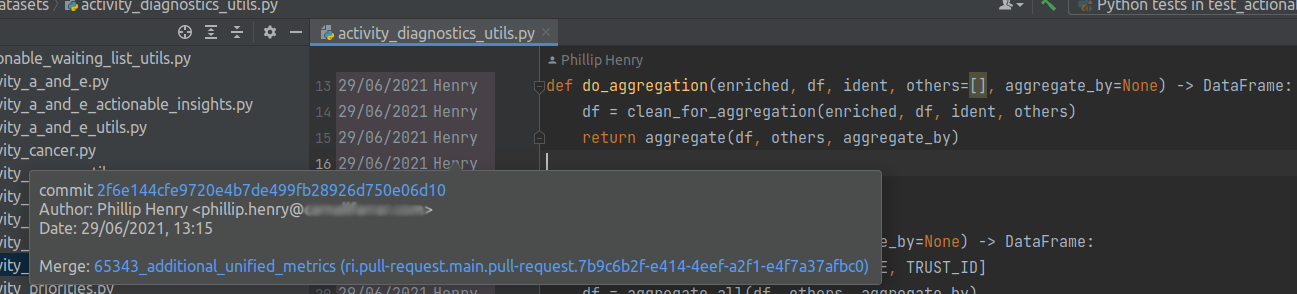
The best thing is that you can tell your code editor to link this code with the ticket with just one click. If future data scientists scratch their head over why you took certain decisions in the machine learning pipeline, they need only click that link and behold!
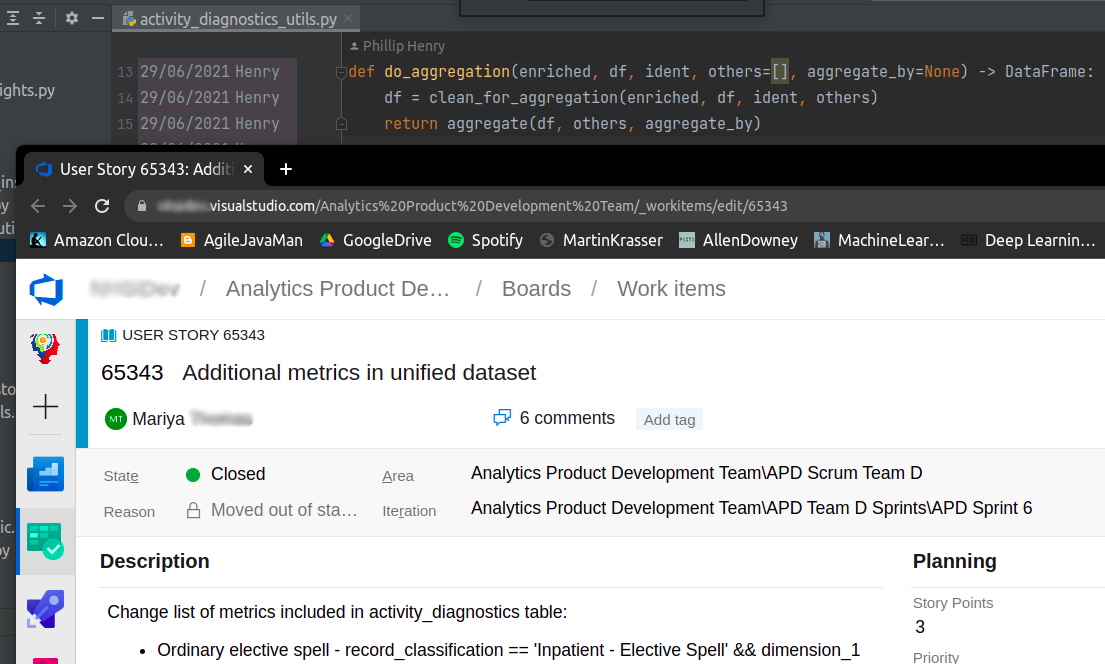
Up pops a browser with the requirements and all the conversations with the business discussing why certain decisions were taken.
OK, you might not be that impressed today. But in a year’s time when you’re wondering why the hell we did things like that, the answer will be just a hyperlink away. And the best bit is: this is true for every single line in your codebase!